第12章 TCP传输控制协议
12.1.1
通信消息差错的解决办法:
- 差错校正码
- 自动重传请求ARQ
12.1.2 重传和重复
重传
处理分组丢失和错误分组的办法是重传分组直到正确接收。发送方发送分组后,等待一个ACK,接收方发送ACK来确认自己收到分组。
可能出现的问题:
- 发送方等待多长时间ACK
- ACK丢失
- 分组收到但出错
重复
在分组中携带序列号,接收方通过序列号判断该分组是否重复
12.1.2 滑动窗口
分组窗口:已发送但还未收到ACK的分组集合
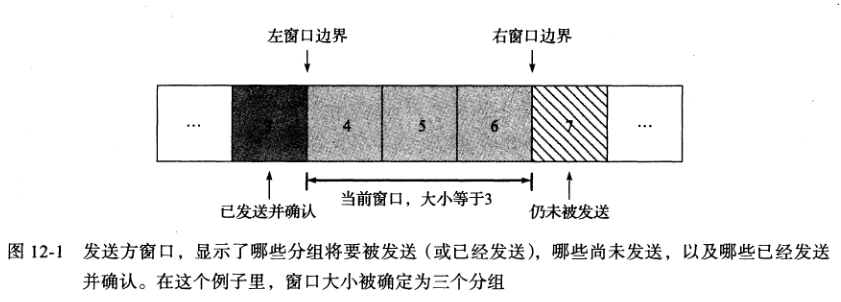
滑动窗口:对于上图中,当收到分组4的ACK后,窗口向右滑动,表示分组7可以被发送
12.1.3 窗口控制
流量控制:当接收方慢于发送方时,控制发送方降低发送速率。
两种方法:
- 基于速率:指定发送方的发送速率,发送方发送速率不会超过该值
- 基于窗口:接收方动态调整窗口大小以通知发送方发送速率
拥塞控制:发送发减低速率以保证不会压垮与接收方之间的网络
12.1.4 超时重传
如何设置超时重传的时间?
统计分组的往返时间,取稍大于平均值。
12.2.1 TCP模型
tcp提供面向连接的,可靠字节流服务
面向连接:tcp在进行数据交互之前,需要建立TCP连接。
字节流:UDP是面向报文的,即应用层交付多长报文,UDP照样发送。TCP面向字节流,即TCP将应用层交付的数据看成无结构的字节流,当发送时,会维护缓冲区,如果交付的数据太长,则划分为多段多次发送;如果交付数据太短,则等待累计到足够的字节再发送。由于TCP会拆分或累计,则会导致数据是没有边界的,当缓冲区够大,可能一次性收到发送方发送的多段数据,这也是TCP拆包和粘包出现的原因。
12.2.2 TCP可靠性
- 序列号:表示每个分组的第一个字节在整个数据流中的字节偏移。比如序列号为301,该报文共100个字节,则表示该报文第一个字节序号为301,最后一个为400,且下一个分组的序号应为401。
- 检验和:包括头部、应用数据、IP头部字段。对于无效的校验和,接收方丢弃该报文,不发送ACK。
- 重传计时器:为一个窗口设置一个重传计时器,当ACK到达时更新。
- ACK:累积确认,指示字节号N的ACK表示所有直到N的字节都收到。
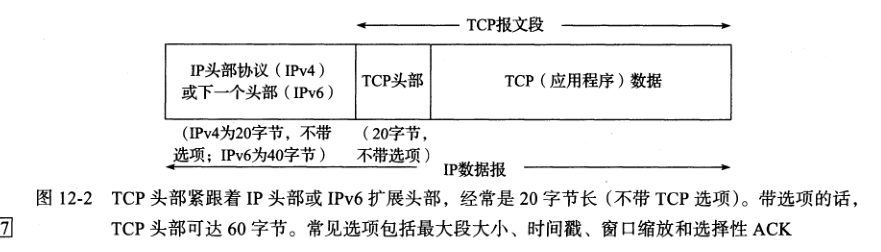
12.2.3 TCP头部和封装
IP数据报封装:
TCP头部:
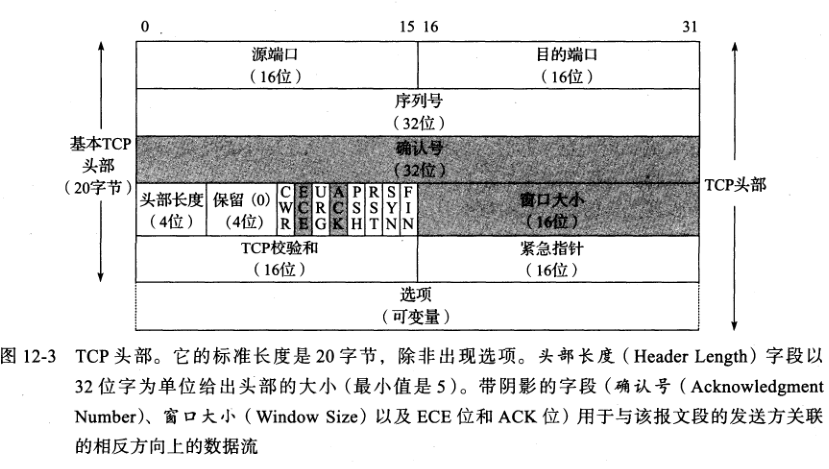
头部特殊字段:
- URG:紧急
- ACK:确认,在连接建立后通常开启
- PSH:推送,未使用?
- RST:重置连接,连接取消
- SYN:初始化序列号,通常是随机选择的
- FIN:发送方结束发送
第18章 TCP的连接与终止
18.2 连接的建立与终止
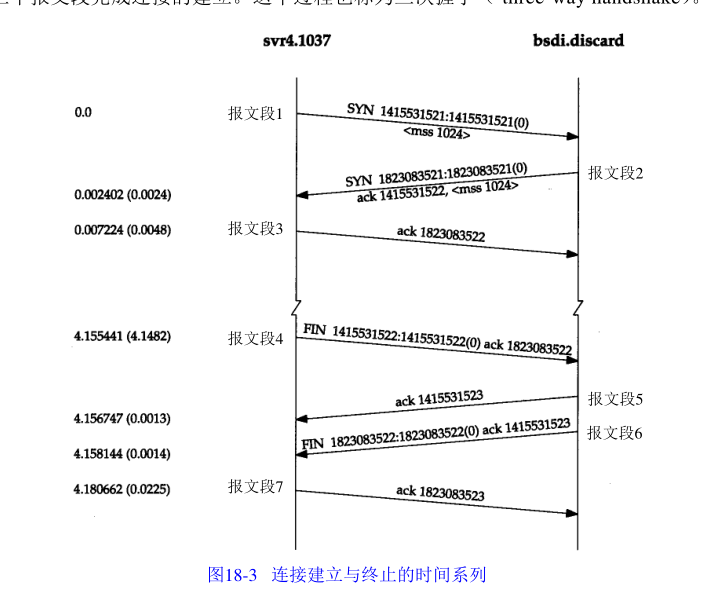
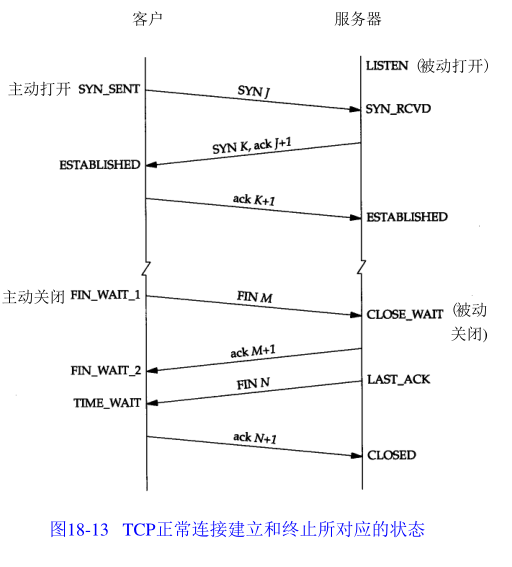
建立连接:
- 客户端发送SYN报文段,并随机生成初始序号。图中为1415531521
- 服务端发送SYN报文段,并随机生成初始序号,确认号设置为客户端的SYN+1。图中SYN为1823083521
- 客户端发送ACK报文段,确认好设置为服务端的SYN+1。
对于初始序号的选择,随机生成,每隔4ms+1。目的是防止在网络中被延迟的分组重传后,接收方做出错误的处理。
终止连接:
由于TCP是全双工,即支持数据在两个方向上流动的,发送一个FIN仅代表着这个方向上没有数据流动,因此终止连接时,每个方向都必须单独关闭
- 客户端发送FIN报文段,主动关闭
- 服务端发送ACK报文段,确认号为客户端FIN序号+1
- 当服务端发送FIN报文段
- 客户端发送ACK报文段,确认号为服务端FIN序号+1
连接超时:
在ubuntu中查看系统变量
# sysctl -a | grep net.ipv4.tcp_syn_retries
net.ipv4.tcp_syn_retries = 6
可以看到SYN报文的重试次数为6,每次的重试时间按2的幂,从1开始。
18.6 TCP状态
状态图:
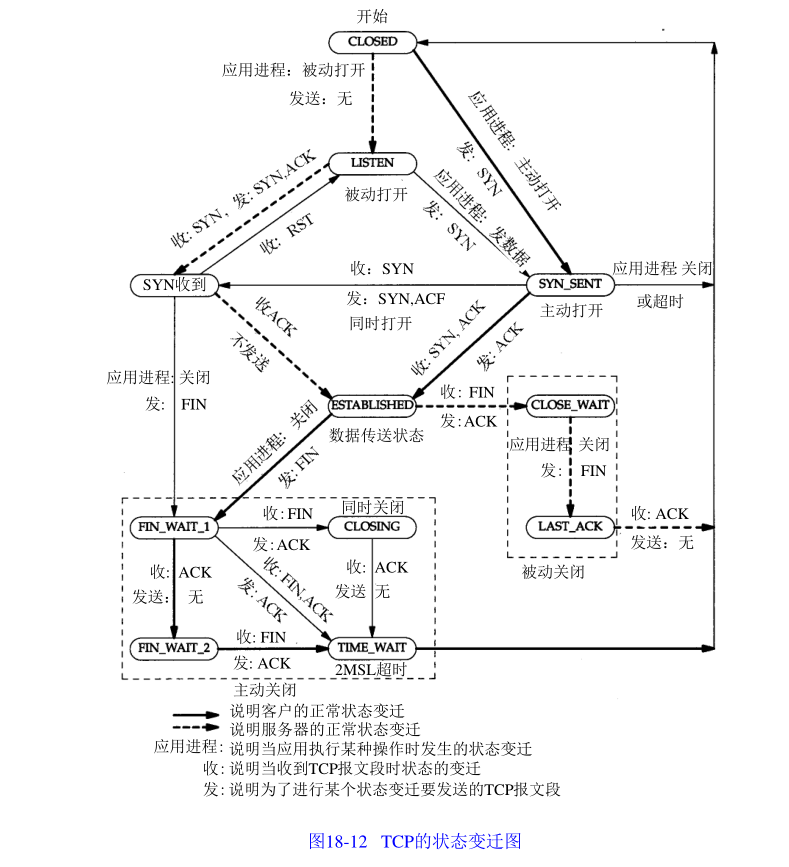
三次握手状态变化:
第三次握手的原因:
挥手等待2MSL的原因:
MSL表示报文段最大生存时间,表示任何报文段被丢弃之前在往网络中生存的最长时间。
在ubuntu系统中查看:
# sysctl -a | grep net.ipv4.tcp.fin_timeout
net.ipv4.tcp_fin_timeout = 60
2MSL=60s,即MSL=30s
18.8 同时打开
状态过程:
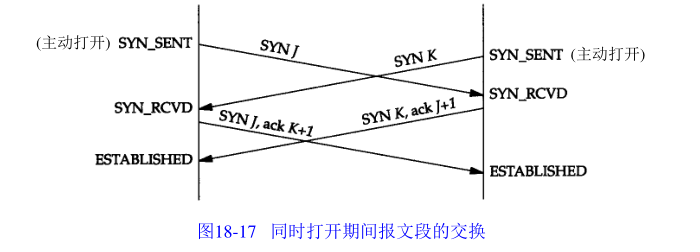
两端同时发送SYN,并都进入SYN_RCVD状态,当收到自己发送的SYN的ACK后,进入ESTABLISHED状态
对于同时连接,只建立一条连接
18.9 同时关闭
状态过程:
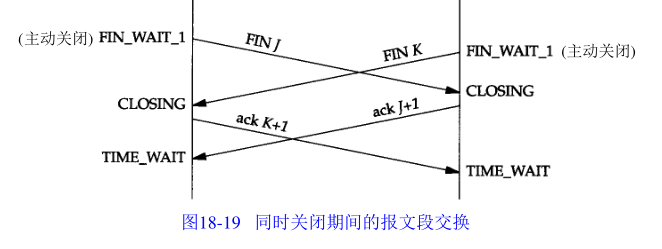
两端同时关闭,从ESTABLISHED状态变为FIN_WAIT_1,并在收到FIN的ACK后,进入TIME_WAIT状态
18.11 请求队列
内核为每个监听套接字维护两个队列:
- 未完成连接队列:已由某个客户端发出SYN,服务端正在等待完成三次握手,这些套接字处于SYN_RCVD状态
- 已完成连接队列:已完成三次握手的套接字,这些套接字处于ESTABLISHED状态
当客户端发出SYN,服务端接收到后,在未完成队列中创建新项;当三次握手中的客户端ACK到达时,将该项移入已连接队列中。服务端调用accept函数时,从已连接队列中获取一项。
对于新的连接请求SYN,如果在队列中没有空间,则TCP会拒绝此次连接,客户端由于无法收到SYN的ACK将会尝试重传。
参数net.core.somaxconn = 128控制已完成连接队列长度。
实验情况一:
环境:设置somaxconn为3,发起10个连接请求。
# ss -lnt | head -1;ss -lnt | grep 7080
# Recv-Q表示当前全连接队列大小,即已经完成三次握手的连接数
# Send-Q表示全连接最大队列长度
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 4 3 :::7080 :::*
结果:服务端中只有4个连接是建立状态,后续连接被丢弃。在客户端中会提示大于4个连接被建立,但后续的连接会有提示未建立失败。
后续连接是否丢弃的处理由参数net.ipv4.tcp_abort_on_overflow = 0控制,默认为0,直接丢弃
半连接长度,由参数net.ipv4.tcp_max_syn_backlog = 1024以及somaxconn控制,有多种判断条件,不单单看backlog就能判断。超出限制,在没有syncookies时会将连接请求的SYN丢弃。
https://www.cnblogs.com/xiaolincoding/p/12995358.html
第19章 TCP的交互数据流
19.3 延时确认
通常TCP在接收到数据时,不是立即发送ACK;而是等待一段时间以便将ACK和本方向上的数据一起发送。
19.4 Nagle算法
为了解决小分组报文的频繁发送对网络造成的拥塞,发送1字节的数据需要加上20字节IP头部和20字节TCP头部,而造成浪费。
Nagle算法要求在一个TCP连接上至多有一个未被确认的小分组,在收到该小分组的确认前不能发送其他小分组。在未收到确认前,缓存等待发送的小分组,当收到确认后,将这些缓存统一构建分组发送。
linux源码中的Nagle算法检查:
分组发送条件:
- 数据大小达到MSS(Maximum Segment Size)最大报文长度
- 该报文包含FIN字段
- TCP_CORK未设置,且TCP_NODELAY设置(该配置用于关闭Nagle算法)
- TCP_CORK未设置,所有之前发送的小分组都收到确认
/* Return false, if packet can be sent now without violation Nagle's rules:
* 1. It is full sized. (provided by caller in %partial bool)
* 2. Or it contains FIN. (already checked by caller)
* 3. Or TCP_CORK is not set, and TCP_NODELAY is set.
* 4. Or TCP_CORK is not set, and all sent packets are ACKed.
* With Minshall's modification: all sent small packets are ACKed.
*/
static bool tcp_nagle_check(bool partial, const struct tcp_sock *tp,
int nonagle)
{
return partial &&
((nonagle & TCP_NAGLE_CORK) ||
(!nonagle && tp->packets_out && tcp_minshall_check(tp)));
}
CORK算法
CORK会阻塞小分组发送,尽可能构建一个大的分组发送出去。
CORK发送条件:
- 取消TCP_CORK设置
- 缓存的小分组达到MSS
- 阻塞等待达到200ms
第20章 TCP成块数据流
**滑动窗口协议:**允许发送方在停止等待确认前可以连续发送多个分组,由于不必每发一个分组就停止等待,可以提高数据传输效率。
累积确认:接收方不必确认每一个收到的分组,而是累积确认,表示接收方已经正确接收了直到确认序号-1的所有字节数组。例如,A发送序号为501,长度200的分组,B收到后发送确认号为701。
若确认号=N,表示到序号N-1为止的所有数据都已正确收到
20.3 滑动窗口
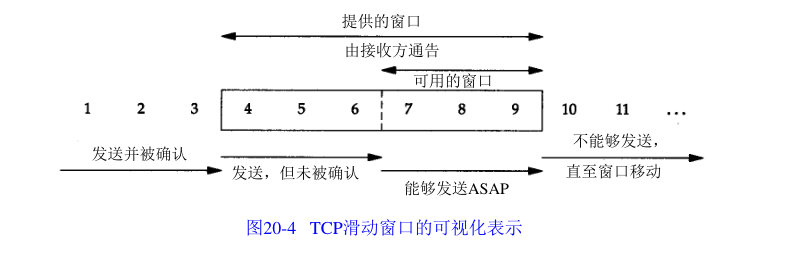
上图说明:
- 序号3及之前的字节数据都已经被正确接收
- 接收方设置的接收窗口大小为6
- 4-6的数据已经发送,但还未收到确认
- 7-9的数据允许发送,但还未发送
窗口运动:
- 当数据被发送和收到确认时,窗口左边沿向右移动,窗口合拢
- 当接收端收到数据,并且上层应用处理后释放TCP接收缓存,窗口右边沿向右移动,表示可以继续发送更多数据,窗口扩张
- 窗口右边沿不可以向左移动收缩窗口
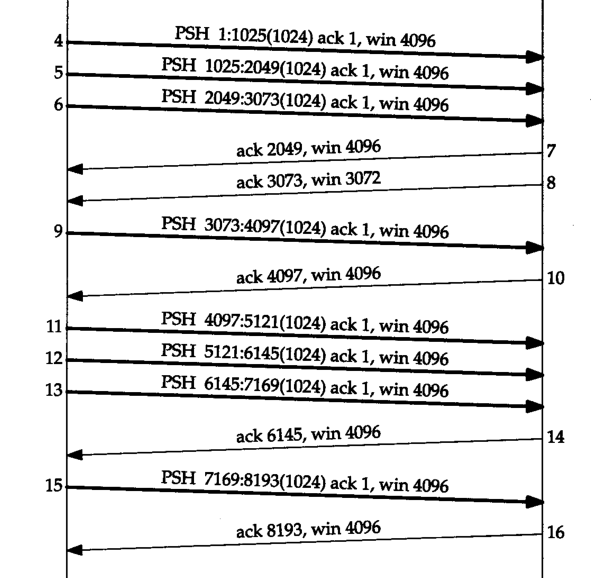
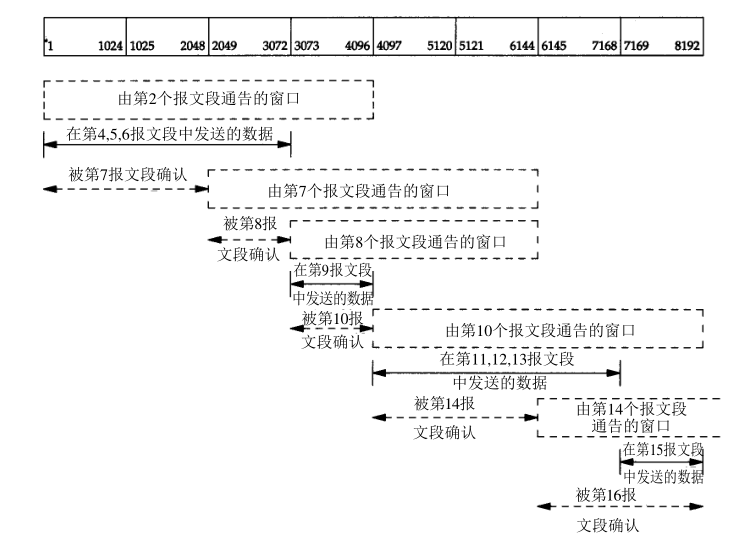
窗口运动例子:
tcp报文发送情况:
tcp滑动窗口运动情况:
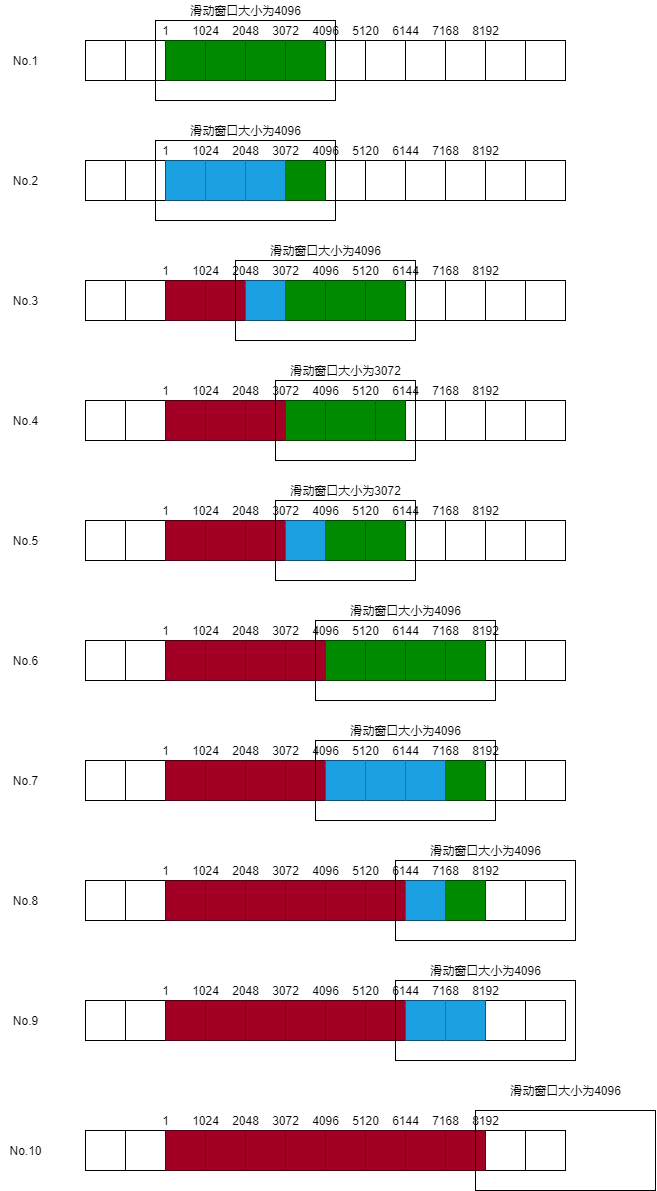
-
绿色表示可用窗口
-
蓝色表示已经发送但未收到确认
-
红色表示已经发送且收到确认
流程解释:
- 初始时窗口大小为4096。
- 发送4,5,6三个报文。此时已发送但未收到确认三个方格,可用一个方格
- 收到7报文确认2049,表示前两个方格确认收到,接收窗口仍为4096,因此窗口合拢扩张。此时已发送但未收到确认一个方格,可用三个方格
- 收到8报文确认3073,表示前三个方格确认收到,且调整窗口为3072,因此窗口合拢。此时可用三个方格
- 发送9报文发送。此时已发送但未收到确认一个方格,可用两个方格
- 收到10报文确认4097,表示前一个方格确认收到,且调整窗口为4096,因此窗口合拢扩张。此时可用四个方格
- 发送11,12,13三个报文。此时已发送但未收到确认三个方格,可用一个方格
- 收到14报文确认6145,表示前两个方格确认收到,因此窗口合拢扩张。此时已发送但未收到确认一个方格,可用三个方格
- 发送15报文。此时已发送但未收到确认两个方格,可用两个方格
- 收到16报文确认8194,表示前两个方格确认收到,因此窗口合拢扩张。
- 发送FIN,连接终止。
- **窗口合拢扩张:**在直观上表现为窗口整体向右移动。
- **窗口合拢:**在直观上表现为窗口左边沿右移,窗口大小减小。
滑动窗口乱序接收
假设在接收方接收数据时,数据报未按序接收到,即可能先发送的数据报在网络中丢弃了,后发送的数据报被接收方正确接收了。
接收方在发送确认时,必须保证只能对按序收到的数据的最高序号给出确认。比如发送1,2,3,4,5.接收方接受到1,2,4,5,报文3在网络中被丢弃了,接收方回应的确认号只能是3,表示1,2都正确收到,不能是6。
在对乱序数据的处理中,通常做法是将不按序到达的数据临时缓存,等待缺少的数据收到后再交付。如果只是单纯的丢弃不按序的数据,将会导致重传较多数据。
第21章 TCP超时与重传
TCP维护4种定时器:
- 重传定时器:期望收到另一端的ACK
- 坚持定时器:使窗口大小信息保持不断流动
- 保活定时器:检测空闲连接的另一端崩溃或重启
- 2MSL定时器:测量TIME_WAIT状态
21.2 超时重传
超时重传时间,倍率关系指数退避
21.3 往返时间测量
记RTT为测量到的报文段往返时间
记RTTS为RTT的加权平均值,平滑处理
则RTTS计算公式:$RTTS = RTTS + g(RTT-RTTS)$,其中因子g通常取0.125,因此新的RTTS与旧RTTS更相关,因此更新较慢
记RTTD为RTT的偏差的加权平均,平滑处理
则RTTD计算公式为:$RTTD = (1-h)RTTD + h|RTT-RTTS|$,其中系数$h$通常取0.25,式中RTTS为旧的RTTS
记RTO为超时重传时间
则RTO计算公式为:$RTO = RTTS + 4RTTD$,式中RTTS为计算后新的RTTS
例子:
RTTS初始为2,RTTD初始为1,测量得RTT为0.5
则新RTTS=2+0.125*(0.5-2)=1.8125
新RTTD=(1-0.25)*1+0.25*|0.5-2|=1.125
则RTO=1.8125+4*1.125=6.3125
Karn算法
重传多义性问题:假定一个分组被发送,在重传时间内该分组的确认未收到,因此发送方重传,然后收到一个该分组的确认,那么如何判断该确认报文是第一个分组还是第二个分组的确认?
对此,Karn算法提出,当发生报文段的超时重传时,不根据该重传的确认来更新RTO,直接忽略。
存在的问题:假设网络突然出现波动等情况,导致产生较大的时延,因此在重传时间内未收到确认,则重传。但由于根据Karn算法,对于重传的报文,不应当采样用于更新RTT,因此导致RTT迟迟不更新。
对此,当发生报文段的超时重传后,将RTO增大一倍,直到不再出现报文段的重传时,才根据上述公式更新RTO
21.6 慢开始与拥塞避免
拥塞控制是基于窗口的拥塞控制,发送方维护一个拥塞窗口cwnd,该窗口大小根据网络拥塞状态动态变化。
由于发送速率不能超过接收方的接收速率,因此还需要考虑接收方的接收窗口cwnd
因此,发送方窗口大小swnd=min(cwnd, rwnd)
慢开始
在初始时,拥塞窗口为1个报文段,当发送方每收到一个报文段的确认时,将拥塞窗口增大1,拥塞窗口的大小是以2的幂次增长。
例子:初始时cwnd为1,因此只能发送一个报文段,当收到该报文段确认后,cwnd+1=2;发送2个报文段,这两个报文段每收到一个确认cwnd就增大1,因此两个确认都收到后cwnd为4;发送4个报文段…
由于cwnd以指数增长,因此为了避免引起网络拥塞,需要设置慢启动门限ssthresh,当cwnd<ssthresh时,使用慢启动;当cwnd>=ssthresh时,使用拥塞避免
拥塞避免
当cwnd达到门限后,当发送方每收到一个报文段的确认时,将拥塞窗口增大1/cwnd,拥塞窗口的大小将以加性增长
例子:ssthresh为16,当cwnd从1,2,4,8,16增大到16时,使用拥塞避免,发送16个报文段,每收到一个报文段确认增加1/16,因此收到全部16个报文段的确认后,cwnd为17
拥塞发生
当拥塞发生时,即出现超时重传或者收到重复确认
如果是出现超时重传,则将门限ssthresh设置为当前cwnd的一半,将cwnd大小重置为1,开始慢开始算法
例子:假设在cwnd增长到24时发生超时重传,则ssthresh设置为24/2=12,cwnd重置为1
如果是出现收到重复确认,则开始快恢复算法
快重传
当接收方收到数据时,不等待自己发送数据时捎带确认,而是立即发送确认。当收到失序的报文段,立即发送对已经收到的报文段的重复确认。当发送方连续收到3个或以上的重复确认时,认为报文丢失,则立即进行重传。
快恢复
将门限ssthresh设置为当前cwnd的一半,将cwnd设置为ssthresh或ssthresh+3,重传丢失的报文段;当继续收到重复的确认时,将cwnd增大1;当收到新数据的确认时,将cwnd设置回ssthresh,继续拥塞避免算法
拥塞避免其他算法
查看linux支持的拥塞控制算法,以及正在使用的拥塞控制算法
# sysctl -a | grep congestion_control
net.ipv4.tcp_allowed_congestion_control = cubic reno
net.ipv4.tcp_available_congestion_control = cubic reno
net.ipv4.tcp_congestion_control = cubic
Reno
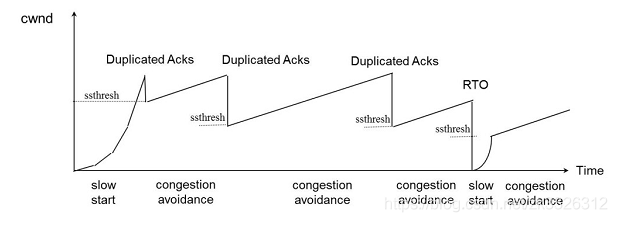
reno包含上述的慢开始、拥塞避免、快重传、快恢复
拥塞发生:
- 超时RTO:进入慢开始阶段
- 重复ACK:执行快重传后,进入快恢复,拥塞避免阶段
适用于低延迟(short RTT)和低带宽(small BDP)的网络环境
cubic
由于在标准TCP的拥塞控制中,如Reno算法,在拥塞发生后,使用线性的窗口增长函数,导致其在大网络带宽环境下网络资源利用率低。
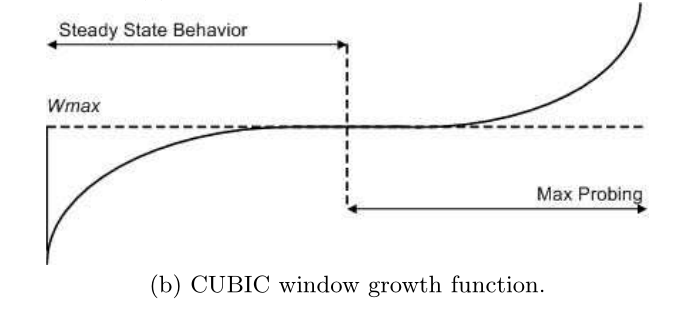
cubic相关函数解释:
窗口增长函数:
$W_cubic(t) = C*(t-K)^3 + W_max$(Eq.1)
C为参数控制窗口增长的速率,t表示距离此次拥塞避免开始经过的时间,K表示假设没有拥塞发生的情况下,拥塞窗口增长到W_max所需要的时间
这里可以考虑一个3次函数y=x^3,通过向上和向右平移得到y=(x-k)^3+c,与上式结构相同
K计算公式:
$K = cubic_root(W_max*(1-beta_cubic)/C)$(Eq.2)
beta_cubic为窗口减小因子,当拥塞发生,拥塞窗口减小为cwnd*beta_cubic
已知,W_cubic(0) = beta_cubic*W_max,因此将t=0带入窗口增长函数中可以求得K。
cubic拥塞窗口
当收到一个ACK,通过上式计算下个RTT的窗口增长速率。(cubic不是与RTT无关?)。计算W_cubic(t+RTT)作为拥塞窗口候选值,并且该RTT是由标准TCP中的加权平均计算的。
根据拥塞窗口cwnd的大小,cubic有三种模式:
- The TCP-friendly region,tcp友好型,确保cubic有着标准TCP相同的吞吐量
- The concave region,当cwnd<W_max,处于凹函数处,即第一段
- The convex region,当cwnd>W_max,处于凸函数处,即最后一段
**TCP友好型区域:**为了使得cubic在低BDP的环境下,能和标准TCP有着相同的吞吐量
窗口计算公式:
$W_est(t) = W_{max}\beta + \cfrac{3(1-\beta)}{(1+\beta)}\cfrac{t}{RTT}$(Eq.3)
在拥塞避免阶段,每收到一个ACK,首先根据式(Eq.1)计算拥塞窗口,然后根据式(Eq.3)计算友好型窗口大小,如果W_cubic(t)<W_est(t),则说明此时在TCP友好型区域,因此拥塞窗口应当设置为W_est(t)以保证更大的吞吐量。
凹区域:在拥塞避免阶段,每收到一个ACK,如果此时不处于TCP友好型区域,且cwnd<W_max,则处于凹区域。此时cwnd的增量计算为(W_cubic(t+RTT)-cwnd)/cwnd,即cwnd更新为W_cubic(t+RTT)
**凸区域:**在拥塞避免阶段,每收到一个ACK,如果此时不处于TCP友好型区域,且cwnd≥W_max,则处于凸区域。当拥塞窗口大于W_max(W_max是拥塞发生时的窗口大小),则说明此时的网络环境已经发生变化,网络带宽可能增大了,因此,可以尝试探测更大的拥塞窗口。在探测阶段,函数首先缓慢增长,并且增长速率逐渐增大,因此函数的增长将越来越快。
拥塞避免
调用tcp_cong_control,调用tcp_cong_avoid,进而调用icsk_ca_ops->cong_avoid
触发cubic中注册的bictcp_cong_avoid函数,对应论文中的On each ACK处理部分
bictcp_update用于计算拥塞窗口,但未更新snd_cwnd
tcp_cong_avoid_ai更新snd_cwnd拥塞窗口
拥塞发生
拥塞发生时:
-
超时丢包:
拥塞状态进入TCP_CA_Loss
调用tcp_enter_loss,调用tcp_set_ca_state改变状态,进而调用icsk_ca_ops->set_state
触发cubic中注册的bictcp_state函数,对应论文中的Timeout处理部分
重置,进入慢开始阶段
static void bictcp_state(struct sock *sk, u8 new_state) { if (new_state == TCP_CA_Loss) { bictcp_reset(inet_csk_ca(sk)); bictcp_hystart_reset(sk); } } -
重复ACK:
拥塞状态进入TCP_CA_Recovery
调用tcp_enter_recovery,调用tcp_init_cwnd_reduction,调用icsk_ca_ops->ssthresh更新snd_ssthresh
触发cubic中注册的bictcp_recalc_ssthresh函数,对应论文中的Packet Loss处理部分
调整拥塞窗口,以及慢开始门限,进入新的拥塞避免阶段(即三阶函数的起始部分)
static u32 bictcp_recalc_ssthresh(struct sock *sk) { const struct tcp_sock *tp = tcp_sk(sk); struct bictcp *ca = inet_csk_ca(sk); ca->epoch_start = 0; /* end of epoch */ /* Wmax and fast convergence */ if (tp->snd_cwnd < ca->last_max_cwnd && fast_convergence) ca->last_max_cwnd = (tp->snd_cwnd * (BICTCP_BETA_SCALE + beta)) / (2 * BICTCP_BETA_SCALE); else ca->last_max_cwnd = tp->snd_cwnd; // snd_cwnd * 717 / 1024 // 717 / 1024 ≈ 0.7 return max((tp->snd_cwnd * beta) / BICTCP_BETA_SCALE, 2U); }
拥塞发生时:
beta_cubic = 0.7
W_max = cwnd
ssthresh = cwnd * beta_cubic
ssthresh = max(ssthresh, 2) // 慢开始门限至少为2个单位MSS
cwnd = cwnd * beta_cubic
快速收敛:
当新的流量加入网络时,网络需要放弃部分旧的流量以保证新流量有增长空间。
当拥塞发生时,将当前拥塞窗口W_max与上次拥塞发生时记录的拥塞窗口W_last_max相比较
if (W_max < W_last_max){ // should we make room for others
W_last_max = W_max; // remember the last W_max
W_max = W_max*(1.0+beta_cubic)/2.0; // further reduce W_max
} else {
W_last_max = W_max // remember the last W_max
}
如果W_max<W_last_max,则说明当前流的饱和度在降低,因此需要进一步减小W_max,以让该流释放更多的带宽。
hybrid slow start
为了解决传统慢开始,在窗口增大到一定程度出现大量丢包的问题。
混合慢开始与传统慢开始一样,窗口以指数增长,但引入了判断机制,从慢开始阶段强制进入拥塞避免阶段
两种判断条件:
- ack train:距离慢开始启动经过的时间,大于RTT的一半,认为网络拥塞
- rtt:当往返时延超过一定值后,认为网络拥塞
进入拥塞避免:
直接将慢开启门限ssthresh设置为拥塞窗口cwnd
第22章 TCP坚持定时器
22.3 糊涂窗口综合症
当发送方应用层产生数据速率低,或者接收方应用层处理缓冲区数据速率低时,或两种情况都有,将会导致TCP的滑动窗口变小,导致每次发送很少的数据,当传输仍需要添加TCP头部和IP头部,传输效率低,增加网络拥塞。
解决:
- 接收方不通告小窗口:当接收方应用处理缓冲区数据后,并不立即发送小的窗口通告,而是等待窗口大小到达MSS或一半的缓存空间大小,否则发送通告窗口大小为0
- 发送方不发送小报文:使用Nagle算法,发送方累积数据直到MSS,或者达到通告窗口的一半大小
关闭窗口的潜在问题
接收方为了等待应用处理数据,可能发送通告窗口大小为0,此时发送方将不能发送数据,如果双方一直互相等待,则造成死锁。
为了避免双方一直互相等待,当发送方接收到0窗口通告后,启动定时器。当定时器超时后,发送只有1个字节数据的窗口探测报文。如果接收方通告窗口大小>0,那么可以进行正常发送数据。
第23章 TCP保活定时器
半开放连接
tcp三次握手完成后,进入ESTABLISHED状态,如果连接的一端已经关闭,而另一端没有感知到,将造成另一端持续等待,这样的连接称为半开放连接
为了检测处理半开放连接,tcp使用保活机制。
保活机制
假定开启使用保活功能的一方为服务端,另一端为客户端
如果一个连接在一定时间内(通常是2h)内没有任何数据传输发送,则服务端发起一个探测报文,服务端根据该报文探测客户端处于如下4种状态之一:
- 客户端正常运行。服务端能收到正常的响应,因此重置保活定时器。
- 客户端已经崩溃,且关闭或在正常重启。服务端不能收到正常响应,因此每隔一定时间(通常是75s)再次发起探测,如果发送10个探测都无响应,则认为客户端关闭,服务端终止连接。
- 客户端已经崩溃,且已经重启。客户端收到探测后,响应一个复位,服务端由于收到复位,终止连接。
- 客户端正常运行,线路不可达。与情况2类似,服务端无法区分,只是表现为无法收到正常响应。
参考
https://www.cnblogs.com/huang-xiang/p/13226229.html
https://www.cs.princeton.edu/courses/archive/fall14/cos561/papers/Cubic08.pdf
https://blog.csdn.net/gh201030460222/article/details/83448824