goroutine调度
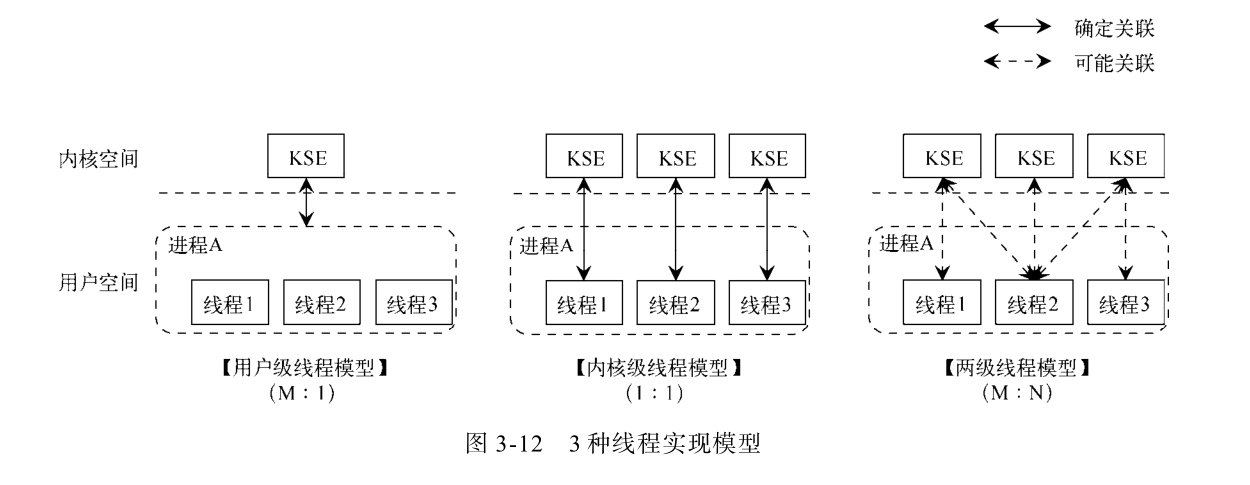
线程实现模型
用户级线程(M:1)
将多个线程放在用户空间中,对应一个系统线程,线程之间由用户空间来进行调度,因此不需要陷入内核状态。但由于内核线程无法感知用户线程,一旦一个用户线程因为某些原因阻塞,则整个进程就阻塞,即使其他线程是可以运行的。由于没有时间中断,因此一个线程开始执行,那么其他线程将无法执行,除非运行的线程主动让出cpu进行新的调度。
内核级线程(1:1)
将一个用户线程对应一个内核线程,线程由内核进行调度。当用户进程的一个线程阻塞时,内核可以调度其他线程来运行。但由于一个用户线程对应一个内核线程,因此线程之间的调度需要进入内核状态,并且用户线程过多的启动新线程,会影响系统对线程的调度性能。linux使用该线程模型。
混合线程(M:N)
将用户线程与内核线程多路复用,一个进程与多个内核线程关联,多个用户线程可以运行在一个内核线程上。内核只需要调度内核线程,用户线程之间的调度由用户空间完成。
x:y表示x个用户线程对应y个内核线程
GMP调度模型
G表示goroutine,M表示machine,P表示processor
G
G的结构体定义在runtime2.go#L406
type g struct {
stack stack // 表示该g的栈内存
m *m // 指向当前m
sched gobuf // 调度上下文,用于协程调度上下文的切换
startpc uintptr // 指向groutine的function
atomicstatus uint32 // 表示该g的状态
}
// 栈内存地址[lo,hi)
type stack struct {
lo uintptr
hi uintptr
}
G的几个状态
| 状态 | |
|---|---|
| _Gidle | G已经被分配,但未被初始化 |
| _Grunnable | G已经在执行队列中等待执行 |
| _Grunning | G可以执行用户代码,拥有了栈,并且分配了M和P |
| _Gsyscall | G在执行系统调用,未在执行用户代码分配了M |
| _Gwaiting | G阻塞,未执行用户代码,未处在等待队列中 |
| _Gdead | G不再被使用,可能由一个G刚刚退出,或者在空闲队列中,或者是仅仅被初始化 |
| _Gcopystack | G正在发生栈复制,未执行用户代码,未处在等待队列中 |
| _Gpreempted | G被抢占,需要通过CAS将状态变为_Gwaiting等待唤醒》 |
每个goroutine都维护着一个自己的栈区,初始大小为2KB,当goroutine运行时,栈空间不足则会触发morestack,因此就会初始化一块两倍大小的栈空间,然后进行栈复制过程,所以这里会将G状态改为_Gcopystack
M
M对应操作系统中线程,最多只有GOMAXPROCS个线程在活跃执行。
type m struct {
g0 *g // 初始线程的栈保存在g0中,并且g0参与调度过程
curg *g // 当前在该m上运行的g
p puintptr // 正在运行用户代码的处理器p (nil if not executing go code)
nextp puintptr // 暂存的处理器p
oldp puintptr // 进入系统调用前保存的处理器p
}
调度器可以创建最多10000个线程。runtime/proc.go#L558
func schedinit() {
...
sched.maxmcount = 10000
...
}
type schedt struct {
maxmcount int32 // maximum number of m's allowed (or die)
}
P
P表示golang中的逻辑处理器,包含了运行G的资源。处理器P的数量等于GOMAXPROCS,即在初始时会创建GOMAXPROCS个处理器P。
P represents a resource that is required to execute Go code.
type p struct {
status uint32 // 表示p的状态
m muintptr // 处理器p当前关联的m
runqhead uint32 // 运行队列头
runqtail uint32 // 运行队列尾
runq [256]guintptr // 处理器p持有的可运行的goroutine队列
runnext guintptr // 下一个运行的g
}
P的几个状态
| 状态 | |
|---|---|
| _Pidle | P未运行用户代码或者调度器,运行队列为空 |
| _Prunning | P与一个M绑定,在运行用户代码或调度器,只有绑定的M可以改变该P的状态 |
| _Psyscall | P未运行用户代码,与进入系统调用的M存在关系(M结构体中的oldp与之关联),但可能会被其他M抢占,并且从该状态切换出来必须通过CAS操作,这里可能会有ABA版本问题,当一个M从系统调用中退出,重新拿回P时,该P可能在系统调用过程中被其他M抢占调用了。 |
| _Pgcstop | 由于GC导致的STW被停止,发起STW的M仍然可以使用该状态的P |
| _Pdead | P不再使用,由于调整GOMAXPROCS会导致P进入该状态 |
当没有其他G可以执行时,转为_Pidle;
当进入系统调用时,转为_Psyscall;
当发生gc是,转为_Pgcstop;
M可以直接将一个P转交给另一个M
特殊的g0和m0
在runtime/proc.go#L83中定义了两个全局变量m0和g0
var (
m0 m
g0 g
)
- m0是golang进程启动时创建的第一个M,并且是由汇编直接复制的。
- g0是每个M都有的一个属性,g0是每个M第一个创建的G,并且g0有更大的栈空间。
proc.go中的全局g0是m0的。g0的作用在于调度其他的G来执行。 - g0的goid为0,在main goroutine创建运行之前,都是由该g0来执行初始化相关操作。
This role is delegated to a special goroutine, called
g0, that is the first goroutine created for each OS thread. Then, it will schedule ready goroutines to run on the threads.
启动过程
程序的入口可以通过gdb调试找到。
// runtime/proc.go#L526
// The bootstrap sequence is:
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
// The new G calls runtime·main.
func schedinit() {
// 设置对M的最大数量的限制
sched.maxmcount = 10000
// 默认创建CPU核心数个P,可通过GOMAXPROCS调整。
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
// 调整全局P队列,扩容/缩容
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
}
call osinit主要任务是获取CPU核心数,os_linux.go中通过获取CPU亲和性掩码来计算call schedinit调度系统一系列初始化- 调用
runtime.newproc创建G,该G是main goroutine,任务函数为runtime.main(proc.go#L114),main goroutine是运行在m0上的,该函数是由main来执行的. call mstart启动M,调用mstart再调用mstart1,并且当前G必须是g0,然后尝试获取一个P,进入调度函数schedule- 在创建第一个main goroutine之前是使用的goid为0的G来做初始化。
创建P的过程
在启动初始化时,schedinit函数会调用procresize函数来对全局的P进行分配初始化。
此外,在用户代码中调用runtime.GOMAXPROCS()函数会STW,然后在重新startTheWorld 时会调用该函数。
- 如果nprocs大于全局P队列allp的容量,则会扩容
- 为新创建的P分配内存
- 如果在是在启动过程中,会将m0与allp[0]绑定
- 释放掉那些不再使用的P
- 截断allp保证P的数量与nprocs一致
- 将当前P以外的P设置为_Pidle,如果该P没有运行任务则加入全局pidel链表中,否则尝试绑定一个M
// runtime/proc.go#L581
func schedinit() {
// 默认创建CPU核心数个P,可通过GOMAXPROCS调整。
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
// 调整全局P队列,扩容/缩容
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
}
// schedinit调用时,old=0,len(allp)=0,cap(allp)=0
func procresize(nprocs int32) *p {
old := gomaxprocs
// nprocs大于现在的全局P数组容量,则需要扩容
if nprocs > int32(len(allp)) {
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}
// 为新创建P分配内存
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
// P初始化,设置状态为_Pgcstop,分配mcache
// id为0的P使用的是mcache0,该mcache0是在mallocinit中初始化的,mallocinit在schedinit中被调用
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
// schedinit中 _g_ = g0, _g_.m = m0, _g_.m.p = 0
// 即此时还没有P
_g_ := getg()
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {
// continue to use the current P
_g_.m.p.ptr().status = _Prunning
_g_.m.p.ptr().mcache.prepareForSweep()
} else {
// release the current P and acquire allp[0].
//
// We must do this before destroying our current P
// because p.destroy itself has write barriers, so we
// need to do that from a valid P.
if _g_.m.p != 0 {
if trace.enabled {
// Pretend that we were descheduled
// and then scheduled again to keep
// the trace sane.
traceGoSched()
traceProcStop(_g_.m.p.ptr())
}
_g_.m.p.ptr().m = 0
}
// 释放当前的P,并将allp[0]与当前M绑定
_g_.m.p = 0
p := allp[0]
p.m = 0
p.status = _Pidle
acquirep(p)
}
// g.m.p is now set, so we no longer need mcache0 for bootstrapping.
mcache0 = nil
// 释放掉不使用的P
for i := nprocs; i < old; i++ {
p := allp[i]
// 将P中的runq任务移动到全局runq队列中,释放其他资源
p.destroy()
}
// 截断allp确保与预设的值相等
if int32(len(allp)) != nprocs {
lock(&allpLock)
allp = allp[:nprocs]
unlock(&allpLock)
}
// 将除当前P以外的P设置为_Pidle
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
if _g_.m.p.ptr() == p {
continue
}
p.status = _Pidle
// 如果该P的运行队列为空,则将其加入全局的pidel链表中
if runqempty(p) {
pidleput(p)
} else {
// 该P运行队列不为空,则尝试关联一个空闲的M
p.m.set(mget())
p.link.set(runnablePs)
runnablePs = p
}
}
return runnablePs
}
创建G的过程
newproc函数调用newproc1获取一个G,然后将该G添加到当前P的runnext中去newproc1函数先尝试在当前P的gFree队列获取一个G- 如果当前P的gFree为空,则会从全局sched的gFree队列中获取G,添加到当前P的gFree队列中。
- 如果获取不到G,则会调用
malg来新建一个G,添加到全局队列allgs中。新创建的G,状态为Gdead都会添加到proc.go中的allgs中,防止被gc扫描清理掉。
- 将拿到的G添加到当前P的runnext中
- 如果main goroutine已经启动,则调用
wakep尝试运行该G。当存在空闲的P,并且没有在自旋的M时,就需要创建新的M来运行G。
// 创建新的G
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
// 系统调用,会切换到系统堆栈,此时使用的g都是m中的g0
systemstack(func() {
// 获取一个G
newg := newproc1(fn, argp, siz, gp, pc)
// 获取当前P
_p_ := getg().m.p.ptr()
// 将新G添加到当前P的runnext中,如果队列满了,则将P的runq的一半移动到全局runq队列中
runqput(_p_, newg, true)
if mainStarted {
wakep()
}
})
}
// 获取一个G
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g {
// 获取当前G,现在为g0
_g_ := getg()
acquirem() // disable preemption because it can be holding p in a local var
siz := narg
// 向上取8的整数倍
siz = (siz + 7) &^ 7
// 参数大小检查
if siz >= _StackMin-4*sys.RegSize-sys.RegSize {
throw("newproc: function arguments too large for new goroutine")
}
// 获取当前P
_p_ := _g_.m.p.ptr()
// 尝试从当前P获取一个G
// 如果当前P的gFree队列为空,则从全局gFree队列获取G(32个),添加到当前P的gFree。
// 优先选择有栈空间的G,其次再选择没有栈空间的G
newg := gfget(_p_)
// 本地队列没有获取到G,则新建一个足够大小的G
if newg == nil {
newg = malg(_StackMin)
// 将状态改为_Gdead
casgstatus(newg, _Gidle, _Gdead)
// 添加到全局allgs队列中
allgadd(newg)
}
// 参数复制到新G的栈空间
memmove(unsafe.Pointer(spArg), argp, uintptr(narg))
// 清理G的sched字段,并重新赋值
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
// 将状态改为_Grunnable
casgstatus(newg, _Gdead, _Grunnable)
// 获得自增id
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
}
// 将新G添加到当前P的队列中
func runqput(_p_ *p, gp *g, next bool) {
// next为true则将新的G添加到runnext,并将gp指向原来的runnext
if next {
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
gp = oldnext.ptr()
}
// 将gp添加到runq的队列尾
retry:
h := atomic.LoadAcq(&_p_.runqhead)
t := _p_.runqtail
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1)
return
}
// 如果队列满了,则需要将队列的一半G移动到全局runq队列中
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
// P的本地队列满时,将一半G移动到全局runq队列中
func runqputslow(_p_ *p, gp *g, h, t uint32) bool {
var batch [len(_p_.runq)/2 + 1]*g
// 获取当前P的runq队列的一半,并检查一次队列是否满
n := t - h
n = n / 2
if n != uint32(len(_p_.runq)/2) {
throw("runqputslow: queue is not full")
}
// 依次移动到临时队列中
for i := uint32(0); i < n; i++ {
batch[i] = _p_.runq[(h+i)%uint32(len(_p_.runq))].ptr()
}
if !atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return false
}
// 将新G添加到临时队列中
batch[n] = gp
// 将队列中的G重新连接起来,schedlink表示下一个G
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
// 构建临时G队列,添加到全局runq队列中
var q gQueue
q.head.set(batch[0])
q.tail.set(batch[n])
globrunqputbatch(&q, int32(n+1))
return true
}
// Tries to add one more P to execute G's.
// Called when a G is made runnable (newproc, ready).
func wakep() {
// 如果没有空闲P的则返回
if atomic.Load(&sched.npidle) == 0 {
return
}
// 存在自旋的M则返回
if atomic.Load(&sched.nmspinning) != 0 || !atomic.Cas(&sched.nmspinning, 0, 1) {
return
}
// 当有空闲的P,且没有自旋的M时,说明M不够,则唤醒或者创建新的M来运行
startm(nil, true)
}
唤醒启动M
// 调度唤醒或新建M来,将P挂在M的nextp。当M被唤醒时,与nextp绑定
// 当参数P为nil时,则从空闲P中获取一个
// 当没有空闲的M时需要创建新的M
func startm(_p_ *p, spinning bool) {
lock(&sched.lock)
if _p_ == nil {
// 获取一个P
_p_ = pidleget()
if _p_ == nil {
unlock(&sched.lock)
if spinning {
// 调用方已经将nmspinning自增了,如果这里还是没能找到空闲的P,
// 则将nmspinning减回去,然后return
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("startm: negative nmspinning")
}
}
return
}
}
mp := mget()
if mp == nil {
// 如果没有空闲的M,则需要放弃全局锁,然后新建一个M
// 但一旦放弃了全局锁,其他的可运行的G会发现没有空闲的P,
// checkdead会发现此时有可运行的G,但没有可运行的M,则会抛出死锁
// 因此这里需要先对新创建的M分配一个ID,并且标记M为正在运行
id := mReserveID()
unlock(&sched.lock)
var fn func()
if spinning {
// 将新M设置为自旋
fn = mspinning
}
newm(fn, _p_, id)
return
}
unlock(&sched.lock)
// 获取到了空闲的M,不创建新的M
// 空闲的M不应该是自旋状态
if mp.spinning {
throw("startm: m is spinning")
}
// 空闲的M没有nextp关联
if mp.nextp != 0 {
throw("startm: m has p")
}
// M自旋时不应该有可以运行任务
if spinning && !runqempty(_p_) {
throw("startm: p has runnable gs")
}
// 设置空闲M的自旋状态,关联nextp,唤醒M
mp.spinning = spinning
mp.nextp.set(_p_)
notewakeup(&mp.park)
}
// 从sched的空闲P链表中获取一个P
func pidleget() *p {
_p_ := sched.pidle.ptr()
if _p_ != nil {
sched.pidle = _p_.link
atomic.Xadd(&sched.npidle, -1) // TODO: fast atomic
}
return _p_
}
// 从sched的空闲M链表中获取一个P
func mget() *m {
mp := sched.midle.ptr()
if mp != nil {
sched.midle = mp.schedlink
sched.nmidle--
}
return mp
}
创建M的过程
newm函数调用allocm分配一个Mallocm函数为新的M分配内存,并且设置M的起始任务函数和id,还要通过malg为该M创建一个G,分配给g0。此外,该函数中还需要清理全局sched的freem列表,将可以删除的M安全的删除掉。newm1函数调用newosproc,创建系统线程,并且分配g0的堆栈为系统线程的堆栈,然后调用当前M的mstart函数
func newm(fn func(), _p_ *p, id int64) {
// 新分配一个M
mp := allocm(_p_, fn, id)
// 设置新M的nextp为当前P,在M调度时会与nextp绑定
mp.nextp.set(_p_)
mp.sigmask = initSigmask
newm1(mp)
}
// 分配新的M的内存,设置起始函数和id,g0
func allocm(_p_ *p, fn func(), id int64) *m {
// release全局的freem列表,如果该M的freeWait为0,则表示可以安全的删除该M,
// 否则不能删除,需要重新链起来放在sched.freem
if sched.freem != nil {
lock(&sched.lock)
var newList *m
for freem := sched.freem; freem != nil; {
if freem.freeWait != 0 {
next := freem.freelink
freem.freelink = newList
newList = freem
freem = next
continue
}
stackfree(freem.g0.stack)
freem = freem.freelink
}
sched.freem = newList
unlock(&sched.lock)
}
// 分配内存
mp := new(m)
// 设置M的起始任务函数
mp.mstartfn = fn
// 设置M的id
mcommoninit(mp, id)
// 新建一个足够大小的G,分配给新建M的g0
if iscgo || GOOS == "solaris" || GOOS == "illumos" || GOOS == "windows" || GOOS == "plan9" || GOOS == "darwin" {
mp.g0 = malg(-1)
} else {
mp.g0 = malg(8192 * sys.StackGuardMultiplier)
}
// g0与M关联
mp.g0.m = mp
return mp
}
// 创建系统线程
func newm1(mp *m) {
execLock.rlock() // Prevent process clone.
// 创建系统线程
// g0 的堆栈是当前这个系统线程的堆栈,也被称为系统堆栈
newosproc(mp)
execLock.runlock()
}
调度开始
mstart调用mstar1mstart1需要确保当前是运行在M的g0上的;如果是m0需要添加信号处理,如果当前M有初始任务函数mstartfn则执行;与P绑定,执行调度scheduleschedule主要任务是获取一个可运行的G,执行execute运行该G- 每隔61次调度,则优先从全局runq队列中获取
- 尝试从当前P获取G,如果当前P有runnext,则获取runnext并继承时间片,否则从runq中获取不继承时间片
- 以上都无法找到则通过
findrunnable阻塞获取一个可运行的G- 尝试从当前P获取
- 尝试从全局runq队列获取
- 不阻塞的从网络IO中获取
- 尝试从其他P中偷一些G
- 以上步骤都没有获取到可运行的G,则会准备调用
stopm休眠 - 再次尝试从全局runq队列获取
- 还是无法获取到,则M与P解绑,P放入空闲队列
- M取消自旋状态,然后检查所有的P是否有可运行的G,如果找到了,就与一个空闲的P绑定,然后回到
findrunnable函数顶部重试获取G - 阻塞检查网络IO,获取G
- 到这里还是无法获取到G,则调用
stopm休眠 - 唤醒后回到
findrunnable函数顶部重试获取G
- 找到可运行的G后,调用
execute执行G - G与M绑定,用户G绑定在M的curg上,G状态切换为_Grunning
- 调用
gogo,将G中的上下文sched恢复到寄存器上运行G - 执行完后调用
goexit(runtime/asm_amd64.s#L1373),goexit在创建G时作为函数的返回地址,因此执行完G中的函数会执行该函数 goexit调用goexit1(runtime/proc.go#L2936),goexit1由于此时是在M的curg的栈上,因此需要先通过mcall(runtime/asm_amd64.s#L293)切换到M的g0栈上,在调用goexit0goexit0将M的curg状态改为_Gdead,与M解绑,清理内存,然后将curg放入当前P的gFree队列中;最后调用schedule进行新的调度
func mstart() {
_g_ := getg()
// Initialize stack guard so that we can start calling regular
// Go code.
_g_.stackguard0 = _g_.stack.lo + _StackGuard
// This is the g0, so we can also call go:systemstack
// functions, which check stackguard1.
_g_.stackguard1 = _g_.stackguard0
mstart1()
}
func mstart1() {
_g_ := getg()
// 确保mstart是运行在M的g0上
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
// 对于m0,还需要添加信号处理
if _g_.m == &m0 {
mstartm0()
}
// 如果有初始任务,则调用
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
// 如果不是m0,则需要与P绑定
if _g_.m != &m0 {
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
schedule()
}
// g0调用schedule
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
_g_ := getg()
top:
pp := _g_.m.p.ptr()
pp.preempt = false
if gp == nil {
// 每隔61次调度,就优先从全局runq队列中获取G
// 否则两个G可以在P的本地队列中互相唤醒
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
// 从当前P中获取一个G
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
// 阻塞找一个可运行的G
gp, inheritTime = findrunnable() // blocks until work is available
}
// 执行G
execute(gp, inheritTime)
}
// 从P本地中拿一个G
func runqget(_p_ *p) (gp *g, inheritTime bool) {
// 如果有runnext,则返回runnext,并且继承上一个G的时间片
for {
next := _p_.runnext
if next == 0 {
break
}
if _p_.runnext.cas(next, 0) {
return next.ptr(), true
}
}
// 从本地队列中获取一个,并且不继承上一个G的时间片,使用新的
for {
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers
t := _p_.runqtail
if t == h {
return nil, false
}
gp := _p_.runq[h%uint32(len(_p_.runq))].ptr()
if atomic.CasRel(&_p_.runqhead, h, h+1) { // cas-release, commits consume
return gp, false
}
}
}
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from local or global queue, poll network.
//
func findrunnable() (gp *g, inheritTime bool) {
top:
_p_ := _g_.m.p.ptr()
// 从P本地获取
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// 从全局runq队列获取
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// 不阻塞,从网络IO中获取
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
}
// Steal work from other P's.
procs := uint32(gomaxprocs)
ranTimer := false
// 如果 自旋的M的数量的2倍 > 正在运行的P的数量,且当前M未在自旋状态,则阻塞自旋
// 为了防止创建过多的P,并且程序的并发很低,过度低消耗CPU资源
if !_g_.m.spinning && 2*atomic.Load(&sched.nmspinning) >= procs-atomic.Load(&sched.npidle) {
goto stop
}
// 将当前M设置为自旋状态
if !_g_.m.spinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
// 从其他P中偷一些G到当前G
for i := 0; i < 4; i++ {
// ...
}
stop:
// 如果全局runq队列不为空,则再次从全局中获取G
if sched.runqsize != 0 {
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
return gp, false
}
// 将当前M的P解绑
if releasep() != _p_ {
throw("findrunnable: wrong p")
}
// 将P放入空闲队列中
pidleput(_p_)
unlock(&sched.lock)
// M取消自旋,再检查所有P,查找可运行的G
// !!!必须先取消自旋再检查allp
wasSpinning := _g_.m.spinning
if _g_.m.spinning {
_g_.m.spinning = false
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("findrunnable: negative nmspinning")
}
}
// 再检查一次allp,如果P有任务,则与P绑定,然后跳转到top,从本地P获取G
for _, _p_ := range allpSnapshot {
if !runqempty(_p_) {
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
break
}
}
// 阻塞,再次检查网络IO
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
// ...
}
// 将M放入全局空闲队列中
stopm()
goto top
}
// 调度G在当前M上运行,inheritTime表示是否继续使用之前的时间片
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// G与M绑定,G切换为_Grunning状态
_g_.m.curg = gp
gp.m = _g_.m
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
// 不继承时间片,则调度次数+1
if !inheritTime {
_g_.m.p.ptr().schedtick++
}
gogo(&gp.sched)
}
// gogo -> goexit -> goexit1 -> goexit0 -> schedule
// gogo 将G的sched恢复到寄存器中,恢复函数执行
// goexit0 将M的curg状态切换为_Gdead,与M解绑,将curg放入当前P的gFree队列中,
// 如果当前P的gFree队列大于64,则将一部分G移动到全局空闲G队列中
// schedule进行新一轮的调度
sysmon
sysmon的创建启动
在runtime/proc.go#L134,main goroutine会在系统栈上调用该函数,创建一个新的OS线程来运行sysmon
systemstack(func() {
newm(sysmon, nil, -1)
})
检查死锁
sysmon会在启动时调用checkdead()检查一次死锁
// proc.go#L4639
// 死锁检查
// The check is based on number of running M's, if 0 -> deadlock.
func checkdead() {
// 计算当前正在运行的M
// mcount():根据下一个创建的M的id和已经释放的线程数相减,得到系统中存在的线程数
// nmidle:空闲的M nmidlelocked:被锁定的M nmsys:进入系统调用的M
run := mcount() - sched.nmidle - sched.nmidlelocked - sched.nmsys
// 如果正在运行的M的数量大于0,那不存在死锁
if run > run0 {
return
}
// 如果run=0,说明程序运行状态不一致,直接异常
if run < 0 {
print("runtime: checkdead: nmidle=", sched.nmidle, " nmidlelocked=", sched.nmidlelocked, " mcount=", mcount(), " nmsys=", sched.nmsys, "\n")
throw("checkdead: inconsistent counts")
}
// run=0,则继续判断
// 检查全局的allgs,如果存在G是_Grunnable/_Grunning/_Gsyscall,则说明存在死锁,因为存在G运行,但正在运行的M数量为0
grunning := 0
lock(&allglock)
for i := 0; i < len(allgs); i++ {
gp := allgs[i]
if isSystemGoroutine(gp, false) {
continue
}
s := readgstatus(gp)
switch s &^ _Gscan {
case _Gwaiting,
_Gpreempted:
grunning++
case _Grunnable,
_Grunning,
_Gsyscall:
unlock(&allglock)
print("runtime: checkdead: find g ", gp.goid, " in status ", s, "\n")
throw("checkdead: runnable g")
}
}
unlock(&allglock)
if grunning == 0 { // possible if main goroutine calls runtime·Goexit()
unlock(&sched.lock) // unlock so that GODEBUG=scheddetail=1 doesn't hang
throw("no goroutines (main called runtime.Goexit) - deadlock!")
}
// 检查全局allp,检查P的计时器,如果存在等待计时器,则说明没有死锁
for _, _p_ := range allp {
if len(_p_.timers) > 0 {
return
}
}
// 存在死锁
getg().m.throwing = -1 // do not dump full stacks
unlock(&sched.lock) // unlock so that GODEBUG=scheddetail=1 doesn't hang
throw("all goroutines are asleep - deadlock!")
}
定时器
如果现在没有定时器需要触发,且所有处理器都空闲或需要GC时,sysmon会休眠
网络IO
// proc.go#L4705
// 网络IO轮询
// 距离上一次网络IO轮询过了10ms,则轮询一次
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(0) // 非阻塞检查,返回可运行的G的列表
if !list.empty() {
incidlelocked(-1)
injectglist(&list)
incidlelocked(1)
}
}
// 处理网络IO轮询回来的G列表,添加到全局runq队列,并尝试运行
func injectglist(glist *gList) {
// 将所有G状态改为_Grunnable
head := glist.head.ptr()
var tail *g
qsize := 0
for gp := head; gp != nil; gp = gp.schedlink.ptr() {
tail = gp
qsize++
casgstatus(gp, _Gwaiting, _Grunnable)
}
// 如果当前运行的P为nil,将全部G添加到全局runq队列中
// 遍历这些G,如果有空闲的P,则启动G,然后函数返回
// 由于这里是在sysmon中调用的,该监控线程是不需要绑定P的,
// 因此这里的P就是nil,所以略去后面P非nil的处理部分
var q gQueue
q.head.set(head)
q.tail.set(tail)
*glist = gList{}
startIdle := func(n int) {
for ; n != 0 && sched.npidle != 0; n-- {
startm(nil, false)
}
}
pp := getg().m.p.ptr()
if pp == nil {
lock(&sched.lock)
globrunqputbatch(&q, int32(qsize))
unlock(&sched.lock)
startIdle(qsize)
return
}
}
抢占
// proc.go#L4734
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
// 尝试抢占,运行时间过长的G/进入系统调用的P
// 1. P状态为_Prunning/_Psyscall
// 1.1 距离上次调度过了10ms,则调用preemptone抢占当前处理器
// 2. P状态为_Psyscall,如果
// 2.1 P的运行队列不为空
// 2.2 不存在空闲的P
// 2.3 距离上次系统调度过了10ms
// 都会调用handoffp交出P的控制权
func retake(now int64) uint32 {
// 遍历所有的P
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
if _p_ == nil {
continue
}
pd := &_p_.sysmontick
s := _p_.status
sysretake := false
// 如果P在_Prunning/_Psyscall,且距离上一次调度过了10ms,则抢占当前处理器
if s == _Prunning || s == _Psyscall {
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(_p_)
sysretake = true
}
}
// 如果P在_Psyscall,
// 如果P的运行队列不为空 或 不存在空闲的P 或 距离上次系统调用过了10ms,则handoffp交出P的控制权
if s == _Psyscall {
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
if atomic.Cas(&_p_.status, s, _Pidle) {
handoffp(_p_)
}
}
}
return uint32(n)
}
// 将G标记为抢占,设置栈空间为溢出,然后通过发送信号抢占
func preemptone(_p_ *p) bool {
// G标记为抢占
gp.preempt = true
// 设置G的栈空间,将栈空间设置为溢出状态,因此调用newstack来执行抢占
gp.stackguard0 = stackPreempt
// Request an async preemption of this P.
if preemptMSupported && debug.asyncpreemptoff == 0 {
_p_.preempt = true
// 信号抢占
preemptM(mp)
}
return true
}
// 通过检查P的运行队列和全局队列,来尝试startm唤醒M与该P绑定,将该P绑定在M的nextp中,
// 待M唤醒时,会与nextp绑定。
// 如果以上没有符合条件的,则pidleput将P放入空闲队列中pidleput
func handoffp(_p_ *p) {
}
强制GC
// proc.go#L4740
// 距离上一次GC已经过了forcegcperiod(2分钟),则强制进行一次GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
// 距离上一次GC已经过了forcegcperiod(2分钟),则强制进行一次GC
func (t gcTrigger) test() bool {
switch t.kind {
case gcTriggerTime:
if gcpercent < 0 {
return false
}
lastgc := int64(atomic.Load64(&memstats.last_gc_nanotime))
return lastgc != 0 && t.now-lastgc > forcegcperiod
}
}